Content Objects
The GitHub repository for the Homer Multitext (HMT) now contains a staggering amount of data, contributed by more than 100 editors directed by Casey Dué and Mary Ebbott, the project’s Editors, Stephanie Lindeborg, our Project Manager, and the project Architects, Neel Smith and myself. The HMT Blog now contains a wealth of scholarly insights into the nature and history of Greek epic poetry. But the infrastructure for the project has been the particular focus for me and Neel Smith for a decade, which invites the question: Where is this infrastructure? Where is the cool page where readers can explore in detail the transmission of the Iliad? What have we been up to?
The HMT does have pages where readers can examine manuscript pages, sometimes seeing transcriptions mapped to regions-of-interest. There are ways to see what scholia comment on a particular line. There are tools for identifying regions of interest on an image. But the HMT’s online interfaces do not aim to create the kind of presentation seen in various projects with similar aims. The HMT’s infrastructure resides in the CITE Architecture Github page, and almost none of it seems aimed at the end-user experience. Instead, it is all about citation.
I am about to begin a sabbatical, during which I will continue working on this infrastructure, for the HMT and for a project focusing on the text of Plutarch’s Life of Pericles. As I look forward to that, it seemed worthwhile to explain briefly the nature of the “infrastructure”, why it is important, and why it takes so long.
Content-Objects vs. Citation-Objects
In 1990, Stephen DeRose, David Durand, Elli Mylonas, and Allen Renear, thinking about “text” in a digital environment, asked “What is Text, Really?”.1 They suggested that a “text” should be defined as “an ordered hierarchy of content-objects.” A decade later, Neel Smith and Gabriel Weaver proposed an alternate defintion of “text”: “an ordered hierarchy of citation objects.” 2
Both agree on “ordered”—you read a text from the beginning to the end. Both agree on “hierarchy”—The New Testament consists of books, which consist of chapters, which consist of verses; the Iliad consists of 24 books, each consisting of hundreds of poetic lines; &c. The question is “What kind of objects are the fundamental units of a text?”
Content is Hard
Seeing the “atoms” of a text as content seems obvious. Until you try to do anything with that content.
For example (Iliad 16.643, diplomatic edition of papyrus H87):
<supplied>ὥρῃ ἐν εἰαρινῇ, ὅτε τε γλάγος ἄγγε</supplied>α δεύε<unclear>ι·</unclear>
Or (Iliad 2.4, diplomatic edition of the Venetus A, Marcianus Graecus Z. 454):
<choice><reg>τιμήσει</reg><orig>τιμήσῃ</orig></choice>· ὀλέσῃ δὲ πολέας ἐπὶ νηυσὶν Ἀχαιῶν·
What is the content in these examples? The answer must be, “It depends…”.
The Simplest Possible Homer Multitext
I want to leave issues of markup, editorial status, and TEI XML for later. I want to start from the very basics. Typing Greek is hard. And doomed is any effort to produce a corpus of Greek texts, and an infrastructure for working with them, that ignores this fact.
We pursue digital projects mainly because computers are good at counting things. To understand large and complex corpora of texts, literary traditions, and historical languages, we hope to use automated processes to gain insights that human readers might not see. So… counting.
For this example, I have used online sources to create the simplest possible “Homer Multitext”. I looked online for Greek editions of the Iliad and compiled this very short digital library:
- Iliad 1.2, first word. Edition 1: οὐλομένην Homer Multitext Archival edition.
- Iliad 1.2, first word. Edition 2: οὐλομένην Loeb Online
- Iliad 1.2, first word. Edition 3: οὐλομένην Perseus Digital Library
- Iliad 1.2, first word. Edition 4: οὐλομένην Alpheios
- Iliad 1.2, first word. Edition 5: οὐλομένην Υπολογιστικό Κέντρο
- Iliad 1.2, first word. Edition 6: Οὐλομένην Dante.de (TeX file)
I have published this valuable dataset here. Before going any further, I want to say, very clearly, that these are all good editions of the Iliad. Each exists for a different purpose, edited according to different scholarly values, but they are all fine, technically correct, editions. They are all freely available online, so we should be able to work with them.
Let’s explore the Homeric tradition, based on this dataset. We aren’t interested in fancy stuff like lemmatized, morphologically aware searching. We just want to count occurrences of a string.
We can start by finding instances of “οὐλομένην” in our six Iliadic editions. Using Safari, we can type in our search query and hit “Find”:
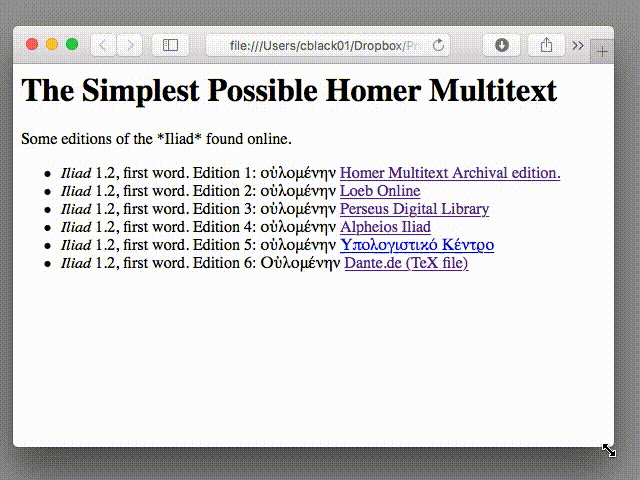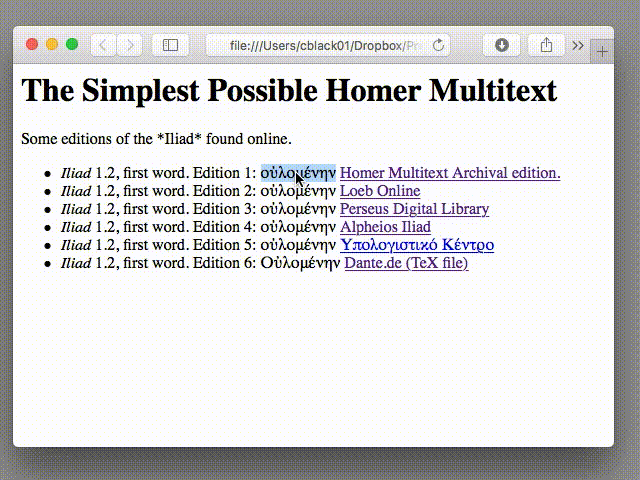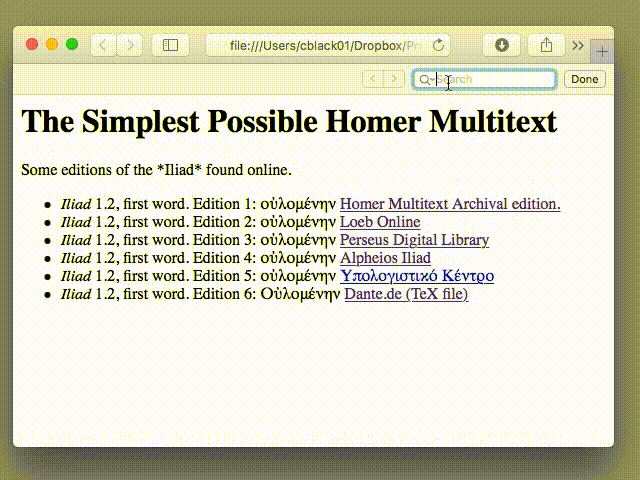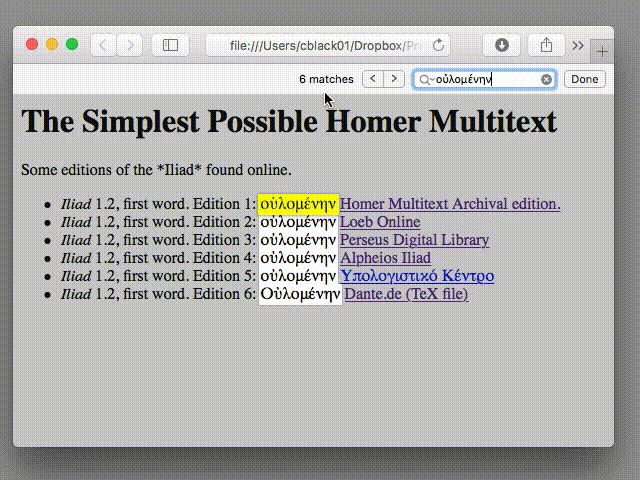
Great! Six instances of οὐλομένην; the word appears in all of our editions.
And because this is just data, we can perform this analysis using various tools, such as a different browser, like Firefox:
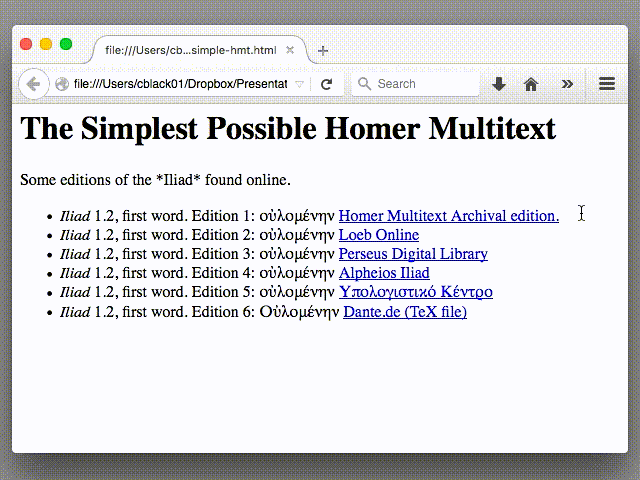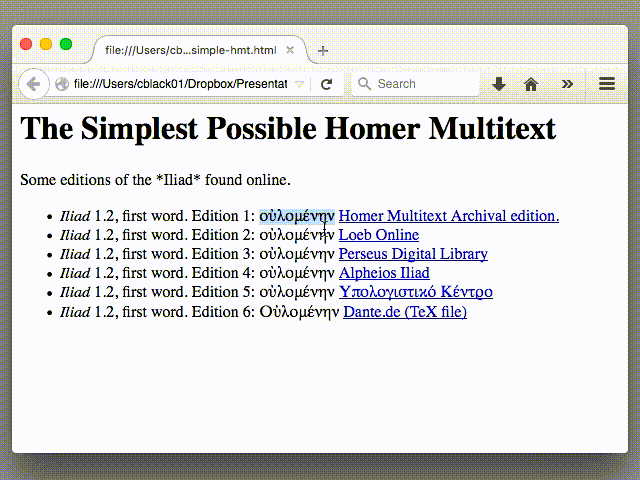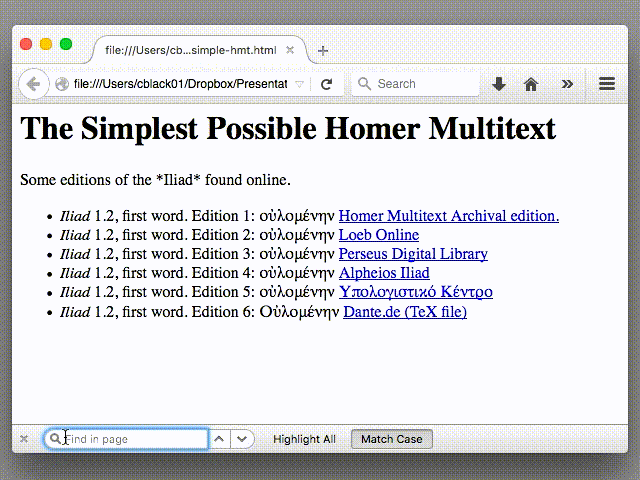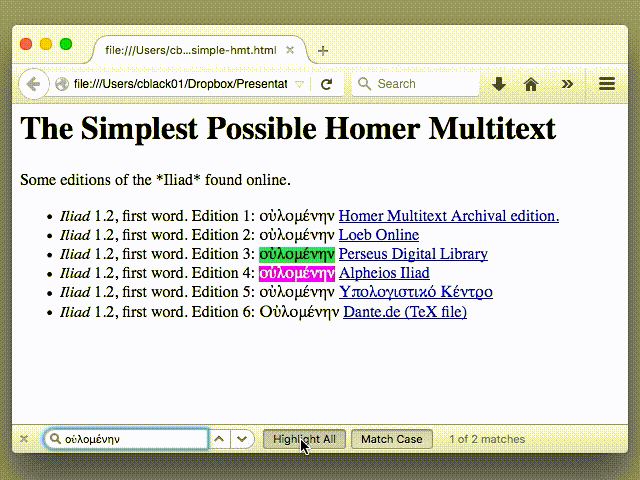
Wait, what happened there? I did this:
- I selected “οὐλομένην” from Edition 1.
- I pasted that string into the “Find” field.
- Firefox “found” the string “οὐλομένην” in Edition 3 and Editon 4, but not in Edition 1.
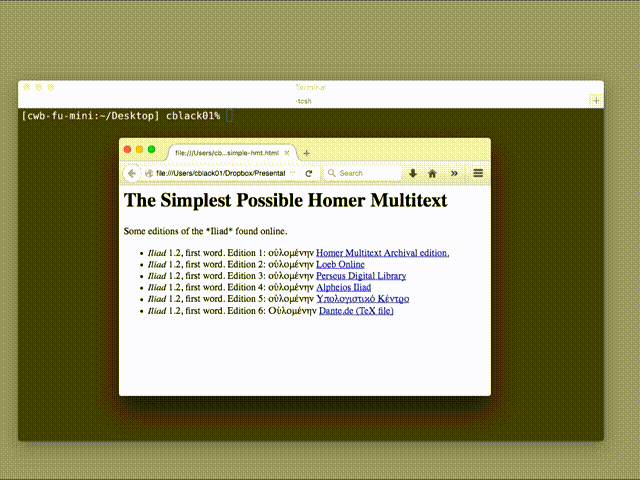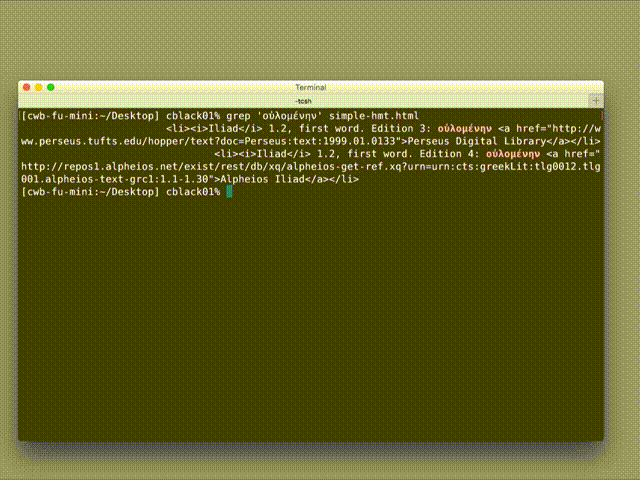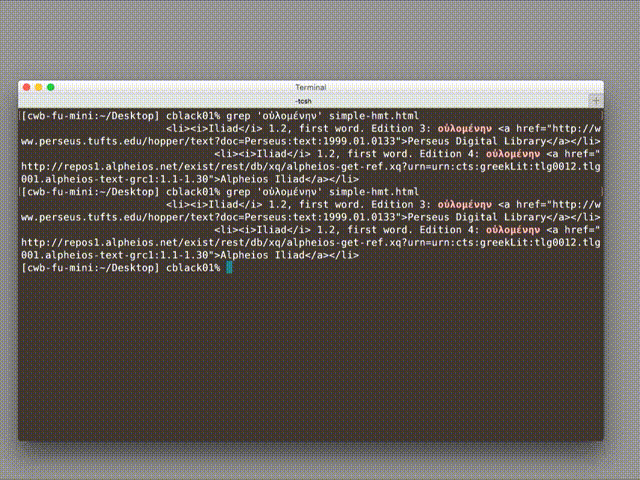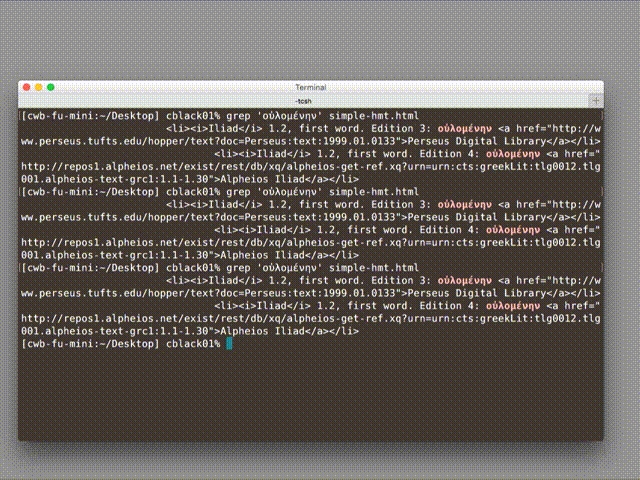
Okay, enough of the kiddie stuff. Let’s use UNIX tools, like real Digital Humanists should. Let’s grep 'οὐλομένην' simplest-hmt.html and see what we get:
Since that .gif is small, and moves fast, here’s what happened:
- I copied “οὐλομένην” from Edition 1.
- I asked
grepto find that string in thesimplest-hmt.htmlfile. grep“found” it in Edition 3 and Edition 4.- When I asked
grepto find the string “οὐλομένην”, copied from Edition 3, the results were the same. - When I asked
grepto find the string “οὐλομένην”, copied from Edition 5, the results were the same.
It is not surprising that a simple string-search should fail to catch “Οὐλομένην”, with an upper-case omicron, from Edition 6; it is actually remarkable that Safari did find it. But both Firefox and grep return counter-intuitive results, failing to “find” a string in the place whence it was copied, but “finding” it in (some) other places.
Enough Belaboring the Point
Obviously, this is a Unicode problem.
0x1F73GREEK SMALL LETTER EPSILON WITH OXIA0x3ADGREEK SMALL LETTER EPSILON WITH TONOS0x3B5GREEK SMALL LETTER EPSILON (with an acute, or tonos??, invisibly combined)
And equally obviously, different engines for searching text handle these cases differently, with Safari happily recognizing them as the “same”, while Firefox and grep… do something. It is entirely possible that the mysteries of the Mac OS X clipboard plays a role here, too. Whatever. We are getting apparently nondeterministic results when searching Greek texts that (1) are found in serious scholarly editions, (2) are perfectly correct according to standards for typing Greek, and (3) are indistinguishable to the human eye.
Canonical Citation
Digital Humanists know that content is difficult. Standardizing markup was the goal of the TEI Standard, and when that standard expanded to serve so many special cases that it ceased to be useful as a standard, many of us were grateful to EpiDoc for stepping in. But the example above shows that all the markup conventions in the world will not allow us to count words without a much more rigorous infrastructure for textual analysis than is afforded by existing standards.
Unicode, bless its heart, is a given, and we can’t expect to effect any fundamental change to how it handles Greek. Nor can we expect digital editions of Greek texts to have more consistency in the future. Our HMT editors are working in the United States and in Europe, on Apple computers, Windows computers, and Linux computers, using various keyboard input systems.
The HMT’s infrastructure has always been based on “canonical citation”, that is, methods for citing texts as precisely or imprecisely as we desire, without regard to any particular technology. In the world of physical books, “John 3:16” is canonical because it works with any edition or translation of the New Testament.
Because in the 21st Century we want to talk about and work with texts very precisely, we need to cite them very precisely, which means being able to cite something like: “The Greek word ‘ουλομένην’ in the HMT’s diplomatic edition of Marcianus Graecus Z.454, Book 1, Line 2.” And we would like to compare that citation to another, such as “The Greek word ‘ουλομένην’ in the Perseus Digital Library’s edition, which follows that of T.W. Allen, Book 1, Line 2.”
We want this comparison to be canonical. We aren’t, actually, interested in a string of Unicode characters, but a series of Greek characters, a word in ancient Greek. It should not matter what technology is used to represent that ancient Greek word.
As part of the CITE architecture, the HMT has published the CITE Library, libraries for working with citations of texts, images, and other data. Among other things, these libraries are aware of the challenges of Unicode. They allow us to manage the unpredictable world of content objects by turning them into editorially managed citation objects.
Using the CITE library, we can cite, e.g.:
urn:cts:greekLit:tlg0012.tlg001.maA:1.2@οὐλομένηνurn:cts:greekLit:tlg0012.tlg001.perseus-grc1:1.2@οὐλομένην
And see that they are identical, as Greek strings.
Just as “John 3:16” is not the same thing as the contents of John 3:16, but a citation to those contents, urn:cts:greekLit:tlg0012.tlg001.maA:1.2@οὐλομένην is not the same as the string “οὐλομένην” as it exists, as Unicode characters, in the TEI-XML file of the Homer Multitext’s diplomatic edition of the Venetus A, but is a very precise and specific citation to that content.
Try it at Home!
For those technically inclined, I have made a small script that demonstrates this aspect of the CTS-URN library. You must have downloaded and installed the Groovy programming language. If you’ve done that, then you can grab the script, put it somewhere, navigate in a Terminal to that place, and type groovy test-cts.groovy.
Reproducible, Valid, Verified
We are trying to make our data reproducible and subject to automated validation and verification by human editors. We are trying to do this from the bottom up, starting at the character level. Thanks to Neel Smith’s tireless (but with this blog post, I hope, not entirely thankless) work on the challenges of Unicode and Greek, we are in a position to work with content by means of citation and get reproducible, valid, and verifiable results.
-
DeRose, Stephen, David Durand, Elli Mylonas, and Allen Renear. “What Is Text, Really?” Journal of Computing in Higher Education 1, no. 2 (Winter 1990): 3–26. ↩
-
Smith, D. Neel, and Gabriel Weaver. “Applying Domain Knowledge from Structured Citation Formats to Text and Data Mining: Examples Using the CITE Architecture.” Text Mining Services, 2009, 129. ↩